
Fine tuning example for transfer learning
Today, I share an example of how to use PyTorch Lightning for transfer learning. We train a variant on LeNet5 on MNIST. That model code is AI-generated, so it might not be a true LeNet, but the exact model does not matter. I wanted a semi-complex convolutional model for MNIST, and LeNet came to mind.. Why MNIST? Because it trains fast on CPU and there are drop in replacement datasets.
We train on the standard MNIST dataset with 10 classes. Then we transfer to a new dataset with 2 classes (even or odd number?), and one dataset with 10 other classes (FashionMNIST). In the new dataset, we only have 200 training samples, so it is very hard to get good generalization if not using transfer learning.
The code became quite long, but I hope it is self explaining. The tricky thing developing this example was tuning the learning rate. Transfer learning needs smaller learning rates than training from scratch.
The results are logged to TensorBoard, and I can see that the transfer learning works. See the image below. The fine-tuned models get better test scores than the models trained from scratch. In all four cases, we train until we get overfitting, and use validation data for early stopping (in practice, we use Lightning model checkpoint ‘best’ to use the early stopping callback).
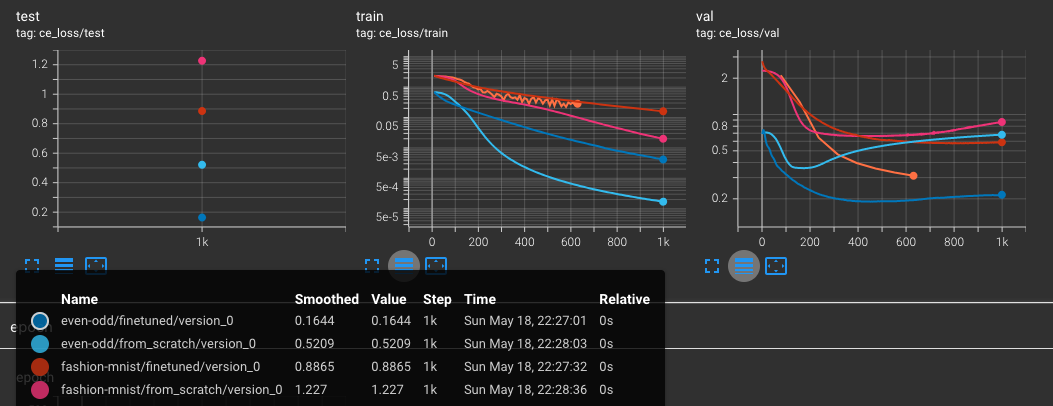
Are the results any good? I don’t really know. Being in the low-data regime, there are other things you could try like data augmentation, or using a more complex model, but that is not the point of this post. Also, the pretrained model seems like it can train for longer, but that is also besides the point.
I hope the code can be useful for anyone (maybe me in the future?) so here it is:
import os
import lightning
import torch
import torchvision
import logging
logger = logging.getLogger(__name__)
LOGDIR = 'pretraining_logs'
LOG_EVERY_N_BATCHES = 10
PRETRAIN_EPOCHS = 50
TRAIN_EPOCHS = 500
def decapitated_lenet():
"""Create LeNet-5 architecture according to Claude (I didnt double check it)"""
model = torch.nn.Sequential(
# First convolution block
torch.nn.Conv2d(1, 6, kernel_size=5, padding=2),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
# Second convolution block
torch.nn.Conv2d(6, 16, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
# Third convolution block
torch.nn.Conv2d(16, 120, kernel_size=5),
torch.nn.ReLU(),
# Flatten
torch.nn.Flatten(),
# I 'decapitate' the model by removing this section!
#torch.nn.Linear(120, 84),
#torch.nn.ReLU(),
#torch.nn.Dropout(dropout_rate),
#torch.nn.Linear(84, n_classes)
)
return model
class LitModule(lightning.LightningModule):
"""A simple model for MNIST classification."""
def __init__(self, label_names: list[str], learning_rate: float = 1e-3):
super().__init__()
logger.info(f"Creating LitModule with label names: {label_names}")
self.save_hyperparameters()
self.n_classes = len(label_names)
self.convnet = decapitated_lenet()
self.classification_head = torch.nn.Sequential(
torch.nn.Linear(120, 84),
torch.nn.ReLU(),
torch.nn.Linear(84, self.n_classes)
)
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, x):
"""Forward pass through the model."""
x = self.convnet(x)
x = self.classification_head(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = self.criterion(y_hat, y)
self.log("ce_loss/train", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = self.criterion(y_hat, y)
self.log("ce_loss/val", loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = self.criterion(y_hat, y)
self.log("ce_loss/test", loss)
self.log('hp_metric', loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
def load_data(target: str, n_train: int):
assert target in ["mnist", "even-odd", 'fashion-mnist'], f"Unknown target: {target}"
if target == "mnist":
label_names = [str(i) for i in range(10)]
elif target == "even-odd":
label_names = ["even", "odd"]
elif target == "fashion-mnist":
label_names = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
transform = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,)),
]
)
if target in ['mnist','even-odd']:
train_and_val_data = torchvision.datasets.MNIST(
root="data",
train=True,
download=True,
transform=transform,
)
test_data = torchvision.datasets.MNIST(
root="data",
train=False,
download=True,
transform=transform,
)
if target == "even-odd":
logger.info("Replacing labels with even/odd")
train_and_val_data.targets = (train_and_val_data.targets % 2).long()
test_data.targets = (test_data.targets % 2).long()
elif target == "fashion-mnist":
train_and_val_data = torchvision.datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=transform,
)
test_data = torchvision.datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=transform,
)
# limit dataset size and make train/val split
idx = torch.randperm(len(train_and_val_data))
train_and_val_data.data = train_and_val_data.data[idx][: int(n_train / 0.8)]
train_and_val_data.targets = train_and_val_data.targets[idx][: int(n_train / 0.8)]
train_data, val_data = torch.utils.data.random_split(
train_and_val_data,
[0.8, 0.2],
generator=torch.Generator().manual_seed(42),
)
# dataset is so small we can have it all pinned in memory
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=128,
shuffle=False,
num_workers=4,
persistent_workers=True,
pin_memory=True,
)
val_loader, test_loader = [
torch.utils.data.DataLoader(
data,
batch_size=32,
shuffle=False,
num_workers=4,
persistent_workers=True,
pin_memory=True,
)
for data in [val_data, test_data]
]
return train_loader, val_loader, test_loader, label_names
def pretrain():
"""Train a model on mnist that classifies all 10 numbers"""
logger.info("Pretraining on all 10 classes in standard mnist")
train_loader, val_loader, _, label_names = load_data(target="mnist",n_train=10_000)
lightning.seed_everything(999)
module = LitModule(label_names=label_names,learning_rate=1e-4)
tb_logger = lightning.pytorch.loggers.TensorBoardLogger(LOGDIR, name="pretrain")
trainer = lightning.Trainer(
max_epochs=PRETRAIN_EPOCHS,
logger=tb_logger,
log_every_n_steps=LOG_EVERY_N_BATCHES,
callbacks=[lightning.pytorch.callbacks.ModelCheckpoint(monitor="ce_loss/val")],
)
tb_logger._default_hp_metric = None
trainer.fit(module, train_loader, val_loader)
checkpoint_path = trainer.checkpoint_callback.best_model_path
logger.info(f"Best model path: {checkpoint_path}")
return checkpoint_path
def train(pretrained_checkpoint: str | None, target: str):
"""Train a model on mnist even/odd or on Fashion MNIST. Maybe from a checkpoint."""
if pretrained_checkpoint is not None:
logger.info(f'Fine tuning from checkpoint: {pretrained_checkpoint}')
else:
logger.info("Training from scratch")
train_loader, val_loader, test_loader, label_names = load_data(target=target,n_train=200)
if pretrained_checkpoint is not None:
ckpt = torch.load(pretrained_checkpoint)
logger.info(f"Checkpoint: {ckpt.keys()}")
logger.info(f"Checkpoint hyperparameters: {ckpt['hyper_parameters']}")
# Load parameters from checkpoint, but drop the classification head
ckpt_state_dict = torch.load(pretrained_checkpoint)['state_dict']
for key in list(ckpt_state_dict.keys()):
if 'classification_head' in key:
del ckpt_state_dict[key]
module = LitModule(label_names=label_names,learning_rate=5e-5)
module.load_state_dict(ckpt_state_dict, strict=False) # we will be missing the classification head, so 'strict' must be False
name = f"{target}/finetuned"
else:
lightning.seed_everything(999)
module = LitModule(label_names=label_names,learning_rate=1e-4)
name = f"{target}/from_scratch"
tb_logger = lightning.pytorch.loggers.TensorBoardLogger(LOGDIR, name=name)
trainer = lightning.Trainer(
max_epochs=TRAIN_EPOCHS,
logger=tb_logger,
log_every_n_steps=LOG_EVERY_N_BATCHES,
)
trainer.fit(module, train_dataloaders=train_loader, val_dataloaders=val_loader)
tb_logger._default_hp_metric = None
res= trainer.test(module, dataloaders=test_loader)
logger.info(f"Test results: {res}")
return res
def main():
logging.basicConfig(level=logging.INFO)
if os.path.exists(LOGDIR):
logger.info("Removing existing log directory")
import shutil
shutil.rmtree(LOGDIR)
os.makedirs(LOGDIR, exist_ok=True)
checkpoint_path = pretrain()
train(checkpoint_path,target='even-odd')
train(checkpoint_path,target='fashion-mnist')
train(None,target='even-odd')
train(None,target='fashion-mnist')
if __name__ == "__main__":
main()